
Post 2 (Webscrapping)
Let’s conduct some webscrapping on the IMDB website!
Here is the post’s general layout:
- Create a Webscrapping Project
- How to Implement a Spider
- Application of the Scraper
You can find all the files I used in my Github repository https://github.com/shizuchanw/IMDB_scraper.
Let’s dive into it!
1. Create a Webscrapping Project
We will be using the python package scrapy for this task. Make sure it’s installed correctly before we start.
To create a scrapy project, type the following command into the commandline tool:
scrapy startproject IMDB_scraper(your project name)
Your commandline tool should give you some instructions like below.
You can start your first spider with:
cd IMDB_scraper
Let’s do what it says by typing “cd IMDB_scraper” in it. We can also open the directory folder by typing the following command:
open IMDB_scraper
Now a webscraper project is created! You can see what files are inside the folder. The main files we’ll be playing around with are settings.py and the spiders folder.
settings.py: settings of our scraper
spiders: what we scrape with
Before we start, let’s put this line of code inside settings.py:
CLOSESPIDER_PAGECOUNT = 20
This line just prevents your scraper from downloading too much data while you’re still testing things out. You’ll remove this line later.
Next, let’s create a spider to do the scraping!
2. How to Implement a Spider
To create a spider, first open the spider folder, then create a .py file for the spider. We will call it imdb_spider.py in this case.
First, let’s import the necessary package.
import scrapy
Second, let’s create a spider class. We can inherite it from the scrapy.Spider module.
Inside the class we will create, here are some variables we are going to use:
name: the name of the spider class. This is important! We will use this to call our spider in commandline tools later.
start_urls: the website that we starr scraping with.
The class we create looks like this:
class ImdbSpider(scrapy.Spider):
"""
This is the class for our spider.
"""
name = 'imdb_spider'
# replace the url with your favorite show
start_urls = ['https://www.imdb.com/title/tt0386676/']
Then we’re going to create 3 parse functions for this class, to parse each website we’ll be visiting.
a. implementation of parse()
Once we start our scraper, the first thing it’ll do is to run the parse() function on the start_urls.
We wish our parse function to do 2 things:
- we want to navigate to the Cast & Crew page
- once we’re there, run parse_full_credits() on that page.
Here we’ll be using a new function called scrapy.Request(). It works like this:
yield scrapy.Request(url, callback = some_function)
url: the url you’re requesting to visit
callback: what you wanna do once you reach that page
Thus the parse function looks like this:
def parse(self, response):
"""
This function is going to parse the start_url.
It navigate to the Cast & Crew page,
then run the parse_full_credits() function.
"""
# the Cast & Crew page url
credit_url = response.url + "fullcredits/"
# the Request function we just learned
yield scrapy.Request(credit_url, callback = self.parse_full_credits)
b. implementation of parse_full_credits()
Now we’re on the Cast & Crew page, and according to the parse() function, parse_full_credits() will be called once we’re there.
We wish to do 3 things here:
- find the actors listed on the page
- go to each of the actor’s page
- once we’re there, run parse_actor_page() on that page.
To achieve the first task, let’s examine the page elements of the Cast & Crew page.
If you’re using the safari browser, right click on the page and select Inspect Elements.
We can see that all the casts are included in a table, with class name cast_list.
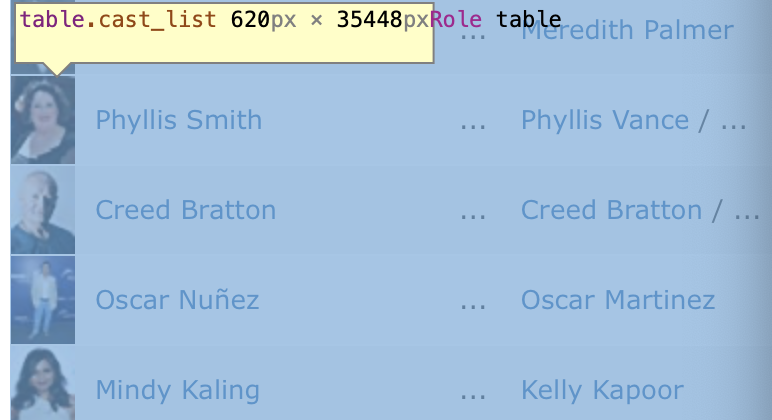
If we look more closely, we can see that links are enclosed by pairs of <tr></tr> tag.
Inside of it are 4 pairs of <td></td> tags, and the links we want is enclosed by the second pair of <td></td>, following the first pair in class “primary_photo”. We want the href attrib of the <a> tag inside it.
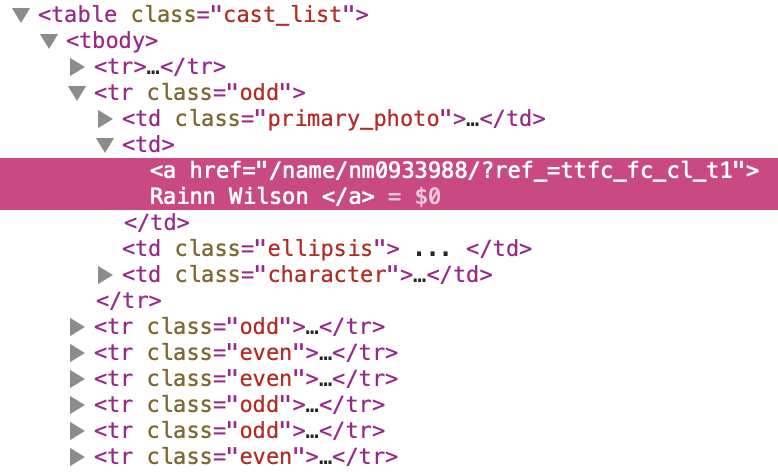
We can use response.css to grab these data with css selectors.
CSS selectors:
A B: select all the B tags inside of A tags
A+B: select all the B right after A
attrib: we can use this to select the href attrib of <a> tags
Thus the css selector for the links would look like this:
response.css("td.primary_photo + td").css("a")
Note that all the actor page urls have the form “https://www.imdb.com/name/nm(number ID)”. Thus we can just attach the href we get with “https://www.imdb.com” to get the url, and yield a scrapy request for each url.
The final function looks like this:
def parse_full_credits(self, response):
"""
This function navigates to each actor's page,
then run the parse_actor_page() function.
"""
# find all url suffices
url_boxes = response.css("td.primary_photo + td").css("a")
# create complete url for each suffix
actor_urls = ["https://www.imdb.com" + url_box.attrib["href"] for url_box in url_boxes]
# for each url, go there and call the parse_actor_page() function
for actor_url in actor_urls:
yield scrapy.Request(actor_url, callback = self.parse_actor_page)
c. implementation of parse_actor_page()
Once we’re on an actor’s page, we with to:
- get the actor’s name
- get all the movies/TV shows the actor was in
- save the info
Let’s first look at the page elements as before.
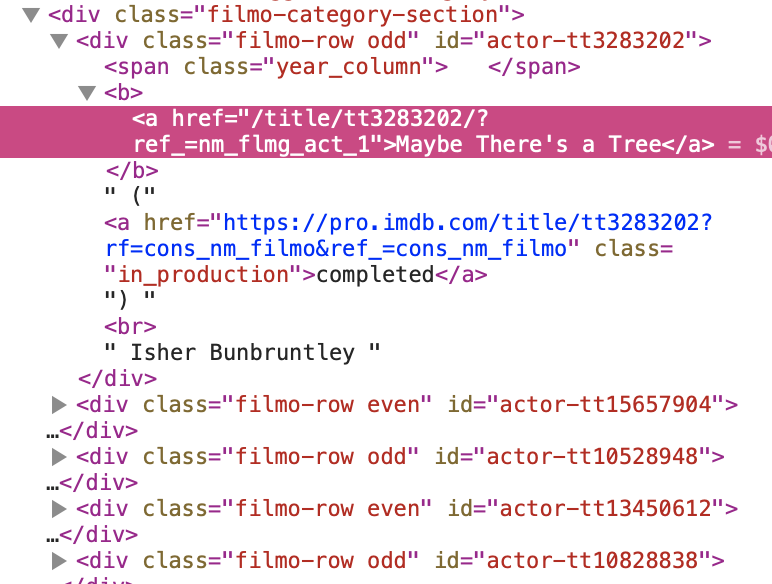
We can see that the actor’s name is enclosed in a pair of <span></span> tags, with class name “itemprop”, and we wish to get the text inside the span tags.

Then the name of the shows are in a pair of <div></div> tags with class name “filmo-category-section”. Note there are a few div tags with this class name, and we only want the information from the first pair.
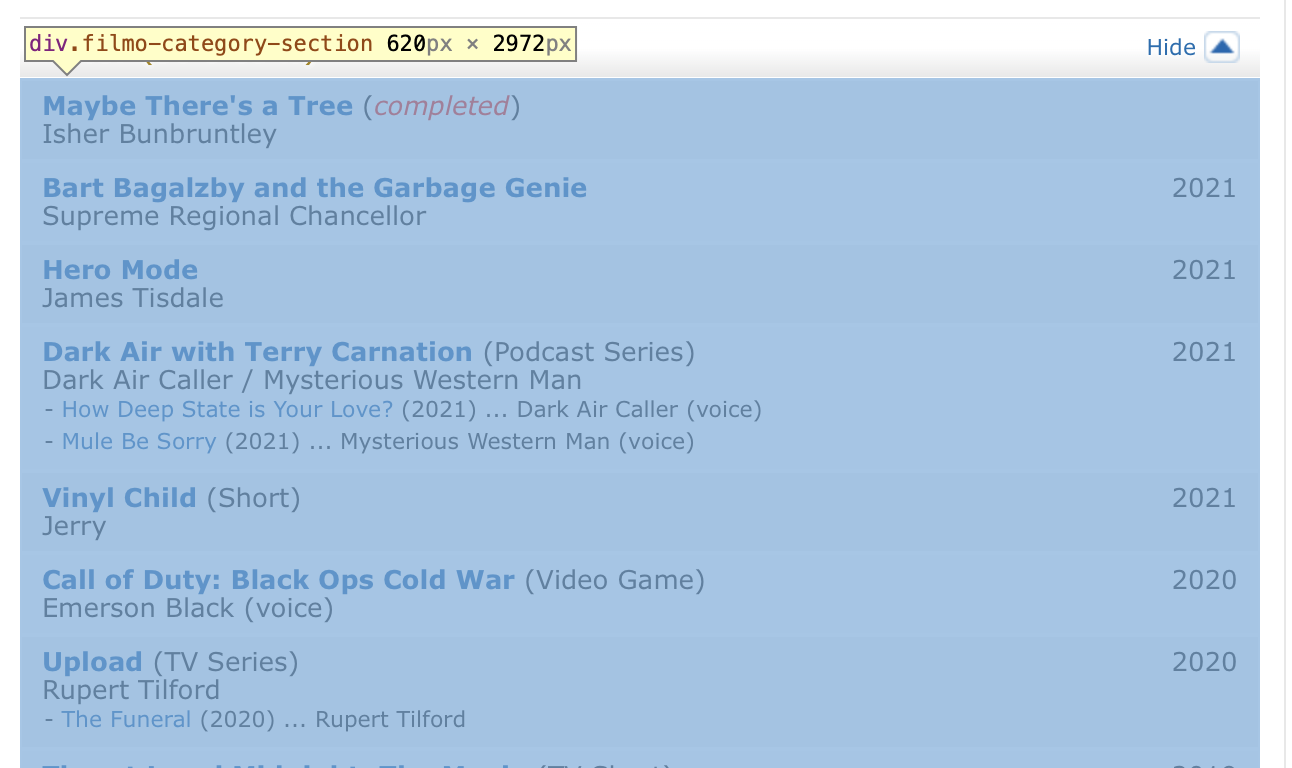
And the movie/TV show name is the text enclosed in a pair of <a></a> tags following a pair of <b></b> tags.
New CSS selectors:
To get the text inside a pair of tags, put ::text right after the selector, and pair it with the get() function.
Thus the selector for the actor name would look like this:
response.css("span.itemprop::text")[0].get()
To get the texts inside all such tags, use the getall() function.
Thus the selector for the movies/TV shows would look like this:
# select the first div with class name filmo-category-section
movie_box = response.css("div.filmo-category-section")[0]
# get all texts inside such tags
movie_box.css("b a::text").getall()
To save the information we found on the page, we also want to use the yield function:
The yield function: It looks like a dictionary, with the format:
yield {
"column_name1": column data1,
"column_name2": column data2
}
It will create a csv file with column headers and corresponding data.
Thus our final function looks like this:
def parse_actor_page(self, response):
"""
This function parses an actor-page,
collects the actor's name and movie/shows info,
then save it.
"""
# find the elements as instructed above
actor_name = response.css("span.itemprop::text")[0].get()
movie_box = response.css("div.filmo-category-section")[0]
movie_or_TV_name = movie_box.css("b a::text").getall()
# save the information
yield {
"actor" : actor_name,
"movie_or_TV_name" : movie_or_TV_name
}
3. Application of the Scraper
Scraping!
Provided that these methods are correctly implemented, you can run the following command to create a .csv file with a column for actors and a column for movies or TV shows.
scrapy crawl imdb_spider -o results.csv
After we do some test runs, and make sure that the spider runs well, we can comment out the line in settings.py we wrote earlier:
CLOSESPIDER_PAGECOUNT = 20
Then command again to scrape more information:
scrapy crawl imdb_spider -o results.csv
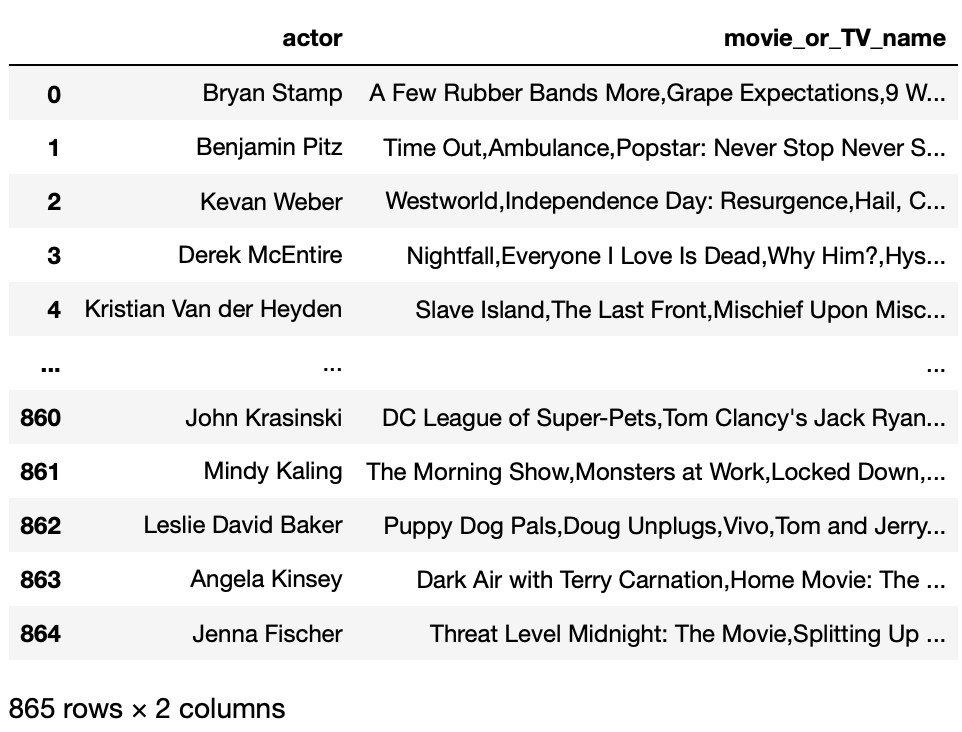
Now we should have a CSV file called results.csv, with columns for actor names and the movies and TV shows on which they worked. I worked on the office (2005)’s IMBd page, and my result looks like this:

Let’s do some quick application with this csv!
Application
We can compute a sorted list with the top movies and TV shows that share actors with your favorite movie or TV show!
First, read the data in jupyter notebook:
import pandas as pd
df = pd.read_csv("IMDB_scraper/results.csv")
df
Output:
Observations & Thoughts:
- The shows are all deliminated by comma in one column. We can separate them with str.split()
- We want to get all of them in one column, so that we can use some functions to count each show later. To do so, we can use the expand then stack() trick: str.split(“,”, expand=True).stack()
- Finally, we can use the value_counts() function on the series to count the appearance of each show/movie.
Thus our code would look like this:
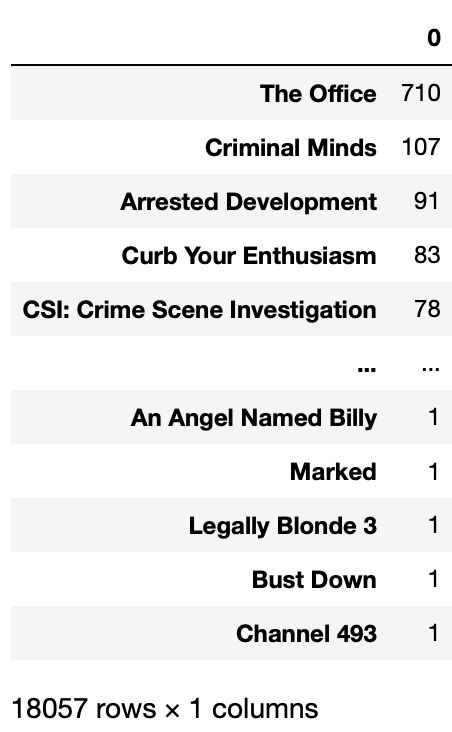
show_counts = pd.DataFrame(df["movie_or_TV_name"] \
.str.split(",", expand=True).stack().value_counts())
show_counts
Output:
Looks good! Let’s clean it up a little bit:
show_counts = show_counts.reset_index()
show_counts = show_counts.rename(columns={"index": "movie/show",
0: "number of shared actors"})
show_counts.head(11)
Output:
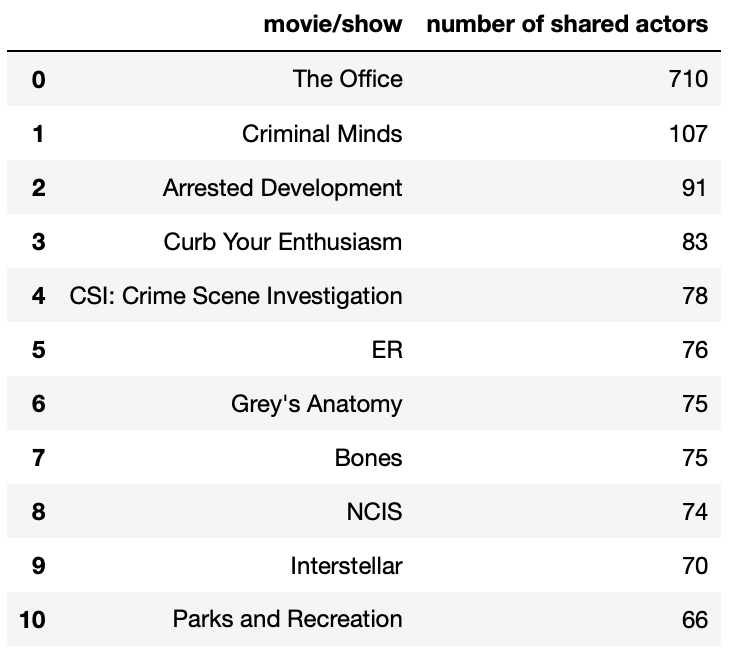
Now we have a list of top 10 shows/movies that share the actors with our favorite show!